llm
1.llm的过程(decoder—only,gpt用,causal modeling)
提示词(prompt)
->分词(tokenizer)
-> 向量化(embedding)
-> transformer : self-attention-> 前向传播得到 logits
-> softmax转化为概率分布
->decoding
->生成token
2.prompt
为了使过程更加形象,引入一个输入文本 text
常见的prompt方式
zero/few shot(实例) prompt。
输入不必多讲,prompt还可用于
• 快速试任务
• 没有训练数据
• 频繁改需求
• 个人使用
3.tokenizer
目前分词有两种形式 world price 和 bpe
- world price 就是将常用词存在一个表中,有输入时就查表,切成词的组合,查不到时标记为“ [UNK] “
- BPE 对于那些查不到的单词来说,就以unicode编码为最小粒度来encode.例如,一个中文字符由三个unicode组成,就把他转化为三个token。
这个时候 text 被tokenizer转化为 input_ids,也就是查表得到的对应的数字。
4.embedding
4.1简介
Word2Vec是一种流行的词嵌入(Word Embedding)技术,由Tomas Mikolov等人在2013年提出。它是一种基于神经网络NNLM的语言模型,旨在通过学习词与词之间的上下文关系来生成词的密集向量表示。Word2Vec的核心思想是利用词在文本中的上下文信息来捕捉词之间的语义关系,从而使得语义相似或相关的词在向量空间中距离较近。
相比于传统的高维稀疏表示(如One-Hot编码),Word2Vec生成的是低维(通常几百维)的密集向量,有助于减少计算复杂度和存储需求。Word2Vec模型能够捕捉到词与词之间的语义关系,比如”国王“和“王后”在向量空间中的位置会比较接近,因为在大量文本中,它们通常会出现在相似的上下文中。Word2Vec模型也可以很好的泛化到未见过的词,因为它是基于上下文信息学习的,而不是基于词典。但由于CBOW/Skip-Gram模型是基于局部上下文的,无法捕捉到长距离的依赖关系,缺乏整体的词与词之间的关系,因此在一些复杂的语义任务上表现不佳。
4.2 CBOW & Skip-Gram
Word2Vec模型主要有两种架构:连续词袋模型CBOW(Continuous Bag of Words)是根据目标词上下文中的词对应的词向量, 计算并输出目标词的向量表示;Skip-Gram模型与CBOW模型相反, 是利用目标词的向量表示计算上下文中的词向量. 实践验证CBOW适用于小型数据集, 而Skip-Gram在大型语料中表现更好。
4.2.1 CBOW
CBOW模型的目标是通过给定的上下文单词来预测目标单词。具体来说,CBOW模型将上下文单词的向量平均,然后通过一个隐藏层和一个输出层来预测目标单词。
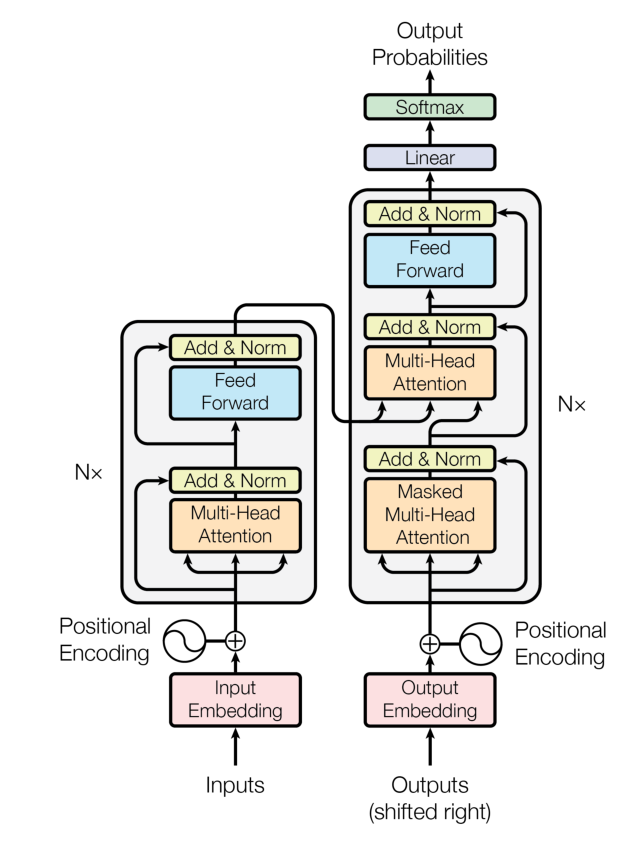
5.transformer
5.1 Attention & sofmax
- 注意力机制是什么?
注意力机制最先源于计算机视觉领域,其核心思想为当我们关注一张图片,我们往往无需看清楚全部内容而仅将注意力集中在重点部分即可。而在自然语言处理领域,我们往往也可以通过将重点注意力集中在一个或几个 token,从而取得更高效高质的计算效果。
attention 在做什么
(multihead是啥?)
定义 Q:查询值 K:键值 V:真值
输入三个token: T1 T2 T3
- step1
embedding已经算好(两个维度)
Q也是给定的一个矩阵,q是其中一个词的向量
根据定义,x中的结果即为每一个q,k进行点积的结果
- step2
对每一个点积的结果进行softmax,也就根据q,k的相似程度分配权重
最后要输出一个
就是权重乘上对应的真值,然后将多个q堆叠
目前,我们离标准的注意力机制公式还差最后一步。在上一个公式中,如果 Q 和 K 对应的维度 d_k比较大,softmax 放缩时就非常容易受影响,使不同值之间的差异较大,从而影响梯度的稳定性。因此,我们要将 Q 和 K 乘积的结果做一个放缩:
5.2 self-attention? multihead -attention
self-attention只关注输入序列之间的关系,为什么要这么做。
例子:
输入
the animal didn't cross the street because it was tired
多头注意力机制是将所有维度拆开,分成好几个头,目的是为了拟合更多的相关关系
如果没有 self-attention ,模型就很难判断出来 animal 和 it 是等价的
5.3掩码自注意力(masked self-attention)
使用注意力掩码的核心动机是让模型只能使用历史信息进行预测而不能看到未来信息。使用注意力机制的 Transformer 模型也是通过类似于 n-gram 的语言模型任务来学习的,也就是对一个文本序列,不断根据之前的 token 来预测下一个 token,直到将整个文本序列补全。
常用在decoder里
5.4前馈神经网络(ffn)
前馈神经网络可以看作多层感知机的一种 :两层mlp 一个前馈神经网络输入 x 经过一次非线性变换进入隐藏层(hidden_dim),再经过一个Relu激活函数,再经过一次非线形变换到输出维度
其中一个线性变换
但由于bias指的是b,bias=false,b=0.
过程
x → W1 → hidden → W2 → output
先升维度再降,提高了表达能力
class MLP(nn.Module):
'''前馈神经网络'''
def __init__(self, dim: int, hidden_dim: int, dropout: float):
super().__init__()
# 定义第一层线性变换,从输入维度到隐藏维度
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
# 定义第二层线性变换,从隐藏维度到输入维度
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
# 定义dropout层,用于防止过拟合(随机把一些神经元设为0)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 前向传播函数
# 首先,输入x通过第一层线性变换和RELU激活函数
# 最后,通过第二层线性变换和dropout层
return self.dropout(self.w2(F.relu(self.w1(x))))5.5 层归一化(layer norm)与残差连接
归一化
核心是为了让不同层输入的取值范围或者分布能够比较一致。由于深度神经网络中每一层的输入都是上一层的输出,因此多层传递下,对网络中较高的层,之前的所有神经层的参数变化会导致其输入的分布发生较大的改变。也就是说,随着神经网络参数的更新,各层的输出分布是不相同的,且差异会随着网络深度的增大而增大。但是,需要预测的条件分布始终是相同的,从而也就造成了预测的误差。
batch norm (批归一化)是将一批(batch) 样本拆分成mini-batch进行归一化,效果不好,主流的方法是层归一化(layer norm),也就是对每一个样本进行归一化 均值
样本方差
其中是为了防止分母为零的稳定项
残差连接
为了防止梯度爆炸,例如梯度是小于一的数,经过好几层的传播(连乘),梯度变成零,提出了残差连接
其中x是上一层的输出,f(x)是经过该层的输出。